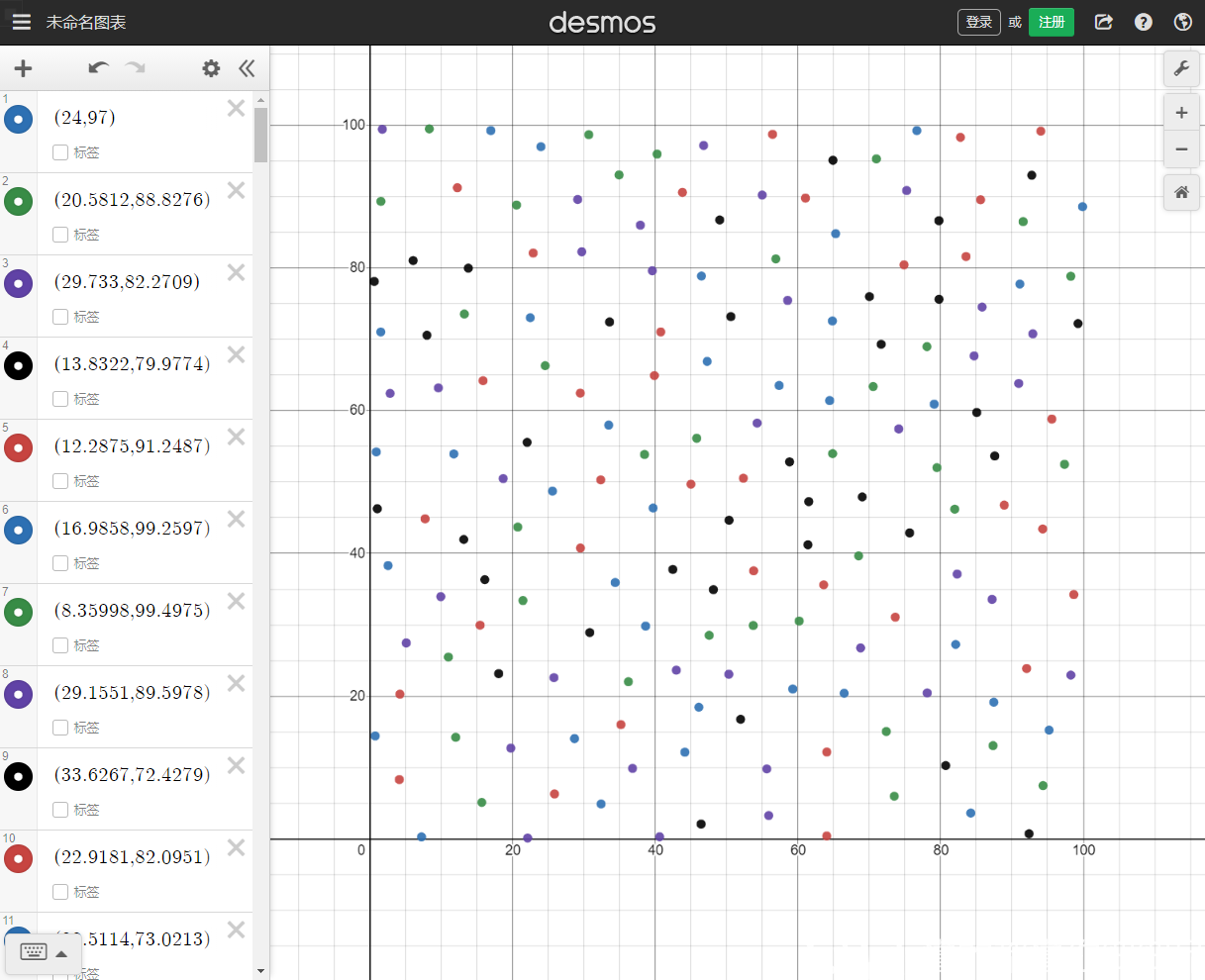
之后便花了点时间百度了一下,找到这个叫快速泊松碟采样(Fast Poisson Disc Sampling)的算法挺符合需求的,但百度上好像没有看到 C++ 的实现,于是我抄实现了个C++的版本作为参考。该版本没有考虑性能,只是能用。
算法思路
算法的核心思想就是对二维平面进行分区,划分成一个个小区块,小区块的斜边长度为两点的间隔 r,因为斜边是一个正方形里最长线段,如果两个点同时出现在一个区块里,那他们的距离必然是小于 r 的,这样就是可以用区块标记表在 O(1) 的时间复杂度下查询出两个点的距离是否过近。算法名字中的 Fast 应该就体现在这里。
算法的大致流程如下。想看算法出处的可以搜索文献 Fast Poisson Disk Sampling in Arbitrary Dimensions 看下。
namespace Random { inlineuint32_tXorShift32() { staticuint32_t seed = time(0); uint32_t x = seed; x ^= x << 13; x ^= x >> 17; x ^= x << 5; seed = x; return x; }
double r = threshold; while (active_list.size() > 0) { // 在已经有的采样集合中取一个点, 在这个点周围生成新的采样点 auto key = active_list[Random::Range(active_list.size())]; // auto key = active_list[0]; auto point = list[key]; bool found = false;
for (int32_t i = 0; i < max_retry; i++) { auto direct = Random::InsideUnitSphere(); // 给原有的采样点 point 加上一个距离 [r, 2r) 的随机向量,成为新的采样点 auto new_point = point + ((direct.Normalized() * r) + (direct * r)); if ((new_point.x < 0 || new_point.x >= range.x) || (new_point.y < 0 || new_point.y >= range.y)) { continue; }
col = std::floor(new_point.x / cell_size); row = std::floor(new_point.y / cell_size); if (grids[row][col] != -1) // 区块内已经有采样点类 { continue; }
// 检查新采样点周围区块是否存在距离小于 threshold 的点 bool ok = true; int32_t min_r = std::floor((new_point.y - threshold) / cell_size); int32_t max_r = std::floor((new_point.y + threshold) / cell_size); int32_t min_c = std::floor((new_point.x - threshold) / cell_size); int32_t max_c = std::floor((new_point.x + threshold) / cell_size); [&]() { for (int32_t r = min_r; r <= max_r; r++) { if (r < 0 || r >= rows) { continue; } for (int32_t c = min_c; c <= max_c; c++) { if (c < 0 || c >= cols) { continue; } int32_t point_key = grids[r][c]; if (point_key != -1) { auto round_point = list[point_key]; auto dist = (round_point - new_point).Magnitude(); if (dist < threshold) { ok = false; return; } // 当 ok 为 false 后,后续的循环检测都没有意义的了, // 使用 return 跳出两层循环。 } } } }();
// 新采样点成功采样 if (ok) { auto new_point_key = list.size(); list.push_back(new_point); grids[row][col] = new_point_key; active_list.push_back(new_point_key); found = true; break; } }
if (!found) { auto iter = std::find(active_list.begin(), active_list.end(), key); if (iter != active_list.end()) { active_list.erase(iter); } } } return list; } } // namespace Random
代码量不少,上方的 Vec2 其实不是必要的,可以替换成只有两个元素的 vector 或者是简单的结构体替代,算法本体中的一些向量运算也可以直接写表达式,不需要调用函数,代码会少一点点。多写个 Vec2 class 单纯就是个人喜好。
下面写个 mian 函数测试下执行效果。
1 2 3 4 5 6 7 8 9
intmain() { auto result = Random::FastPoissonDiscSampling({100, 100}, 6); for (auto p : result) { std::cout << "(" << p.x << "," << p.y << ")" << std::endl; } std::cout << std::endl; }